


Introduction
Everyday, U.S. military and security units receive vast amounts of data collected by intelligence, surveillance, and reconnaissance (ISR) sensors. Human analysts constantly review these data, searching for possible threats. To aid in this effort, researchers from the Georgia Tech Research Institute (GTRI) are helping to improve the capabilities of the nation’s Multi-Disciplinary Intelligence (Multi-INT or MINT) system, which monitors incoming data.
A key to improving the U.S. MINT system involves bringing “actionable intelligence”—information that could require immediate response—to the attention of human analysts as quickly as possible. But finding actionable intelligence is a challenge; it must be identified from a myriad of raw data gathered by intelligence sources, including optical and radar sensors, communications sensors, measurements and signatures intelligence (MASINT), and others.
“The number of analysts is limited, and they can only perform a certain number of actions,” said research analyst Chris Kennedy, who leads the MINT effort. “So out of a huge set of information, which could involve millions of data points, you need to find the most valuable pieces to prioritize for investigation and possible action.”
Accelerating the System
The MINT work addresses two related challenges in the field:
- Network bandwidth and workstation processing power sometimes cannot keep up with incoming data sets that contain terabytes—and sometimes even petabytes—of raw information.
- Human analysts need to stay on top of incoming data by concentrating on the most significant information.
Metadata are small amounts of information that contain the key elements of a data point, which is an individual piece of data. For example, in the case of a car moving down a road, its metadata might consist of the make, model, color, location, speed, and number of passengers. Those attributes are highly informative, yet much easier to transmit and process than, say, a video of the car, which would involve large amounts of data.
The MINT approach (illustrated in Figure 1) creates metadata fields, or leverages existing ones, thereby characterizing each data point with minimal overhead. Then only the metadata are transmitted to the main system for immediate processing; the rest of the raw data are retained in an archive for potential use at a later time.
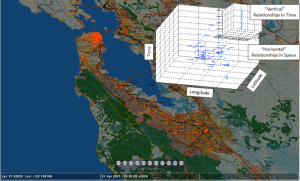
Figure 1: Brightkite Checkins in and Around San Francisco Bay Over a 3-Year Period. MINT Operates on These Data in 23 Minutes.
The metadata technique results in much smaller amounts of information being relayed from ISR sources to computers. That reduction, in turn, reduces processing loads, which helps computers and networks keep up with incoming data. The raw data are also stored and can be examined if necessary.
“Obviously, under this data-reduction approach,” Mr. Kennedy said, “there are information losses that could affect how our program makes decisions, which is why our system is only a tool for, and not a replacement for, the human analyst.”
Informing the Analyst
The second challenge—supporting human analysts—is addressed by methods that improve the system’s ability to identify, compare, and prioritize different types of information. First, the gathered metadata are converted into a single uniform format. By creating one format for all incoming metadata, data points from many different sources can be more readily identified and manipulated. This uniform format is independent of the data source, so different types of ISR data can be processed together.
Then, using the identity-bearing metadata tags, researchers use complex machine-learning algorithms to find and compare related pieces of information. Powerful concurrent-computing techniques allow problems to be divided up and computed on multiple processors. This approach helps the system perform the complex task of determining which data points have been previously associated with other data points.
Other metadata approaches have been used in the past but only for a single intelligence technology, such as a text-recognition program that identifies keywords in voice-to-text data. The MINT program differs from these approaches because it integrates metadata from a variety of intelligence disciplines into a single technology that prioritizes corroborative relationships from multiple sources.
One set of potentially significant signals can be quickly compared to others in the same vicinity to form an in-depth picture. For example, in a disaster relief scenario, one aircraft-mounted ISR sensor might detect information that indicates abandoned vehicles. However, if another sensor detected a functioning communications device in one of the vehicles, that detection would indicate a higher likelihood of finding a survivor, potentially prompting a rescue reconnaissance effort.
The relationship found between the communications device’s signal information and the vehicle’s imagery information would be prioritized against other found relationships and displayed to the analyst on mapping software, such as GTRI’s FalconView program.
Ongoing Improvements
Recently, the MINT team began working with other researchers involved in the development of the Stinger graph-analysis software. Stinger’s capabilities could aid MINT efforts in recording and analyzing information about long-term patterns of observed relationships, such as a type of vehicle and a specific communications device being frequently observed together by independent sensors. This information would then be sent to an analyst through a web-based portal, giving the analyst access to alerts regarding specific kinds of relationships identified by MINT.
The MINT team is presently focused on improving the program’s capacity to process many data points quickly, using three primary sets of testing data involving potentially millions of data points over lengthy time spans. The researchers’ goal is to achieve real-time or near-real-time processing capability, so analysts can be alerted to abnormal information almost instantly.
“We want to get to the point where, as the latest data are coming in,” Kennedy said, “they are being correlated against the data we already have. We need to be able to say to the analyst, ‘OK, you’ve got a million data points, but look at these 10 first.’”