


Introduction
Marine and aerospace vessels have stringent flammability requirements, defined through the American Society for Testing and Materials (ASTM) E1354 Cone Calorimetry standard [1], to protect those onboard Navy vessels in case of fire emergencies. The ASTM E1354 cone calorimeter experiment is a standardized method used to evaluate the fire behavior of materials by measuring parameters such as heat release rate, smoke production, and mass loss.
In this procedure, a small, square specimen is placed horizontally beneath a conical radiant heater, which emits a controlled heat flux, typically ranging from 10 to 100 kW/m². An ignition source like a spark igniter is applied to initiate combustion once the specimen reaches its ignition temperature. Combustion gases are collected through an exhaust system, where oxygen consumption is measured. This allows calculating the heat release rate based on the principle that a known amount of energy is released per unit of oxygen consumed. Additional sensors monitor parameters like carbon monoxide and carbon dioxide production, smoke density, and mass loss rate to assess the material’s flammability characteristics under controlled conditions.
The search for novel, low-flammability polymers has historically been an experimentally intensive effort due to the large amounts of potential formulations, synthesis, and testing required for characterizing their flammability performance via the ASTM E1354 standard [1, 2]. Machine-learning (ML) and deep-learning (DL) methods have proven to be effective in screening molecules for properties unrelated to flammability but have not yet been used for predicting the ASTM E1354 standard properties based on the molecular structure of the polymers of interest [3, 4]. The search for novel polymer formulations with improved flammability performance begins with the molecular structure of the polymer; thus, there is a strong interest in being able to computationally predict their performance due to the extreme amount of potential polymer compositions.
This work combined atomistic density functional theory (DFT) simulations and cheminformatics to predict experimental cone calorimetry results through six different ML and DL models. By creating models based on molecular data, efficient screening of new potential polymer candidates by sidestepping the cost-intensive task of experimental determination of polymer flammability properties for novel formulations with improved performance has been shown. The ML tasks involved predicting four variables defined in ASTM E1354—peak heat release rate (PHRR), average heat release rates (Avg. HRR) at 180 and 300 s, and time to ignition (TTI). An ensemble of six ML models was trained on a corpus of two experimental cone calorimetry databases using both features obtained from DFT simulations of the relevant polymers and those generated using cheminformatics methods.
Developing flame-resistant polymers is an ongoing necessity toward facilitating safe operating conditions for Navy and U.S. Department of Defense (DoD) personnel across all sectors.
Methods
ML/DL methods are as effective as the data that they train on. Thus, collecting and cleaning high-quality data are imperative to developing accurate models of flammability properties. In this section, the datasets used for training the ML/DL models in this work are described.
Datasets
Two datasets were used for training ML models for predicting PHRR, TTI, and Avg. HRR at 180 and 300 s. They are summarized in the following subsections.
Federal Aviation Administration (FAA) Cone Calorimetry Database
This experimental dataset collected by the FAA contained 211 full cone calorimetry experiments for various polymers—19 unique neat resins were observed in this dataset. Most of the polymers had multiple tests for each composition except for polyphthalamide, which only had one cone calorimeter experiment data available. The polymer having the most data available was the PT-30 phenolnovolac cyanate ester composition, with 28 experimental samples. With polymer compositions ranging from polyethylene (having the least desirable flammability properties) to those of the bisphenol C cyanate (the most desirable, having passed MIL-STD-2031 [5]), the dataset broadly covered the range of flammability properties seen in currently known polymer compositions.
Texas A&M University (TAMU) Dataset
Prof. Wang of TAMU built a flame-retardancy database of more than 800 polymeric nanocomposites, including information from polymer flammability, thermal stability, and nanofiller properties [6]. This dataset was included to account for the varying types of fillers and additives that can affect flammability characteristics.
Synthetic Data Generation
DL and ML models greatly benefit from having a large amount of data to train on. This naturally conflicts with the high cost of performing a large amount of physical experiments to create data to train these models. Significant effort was put into hyperparameter tuning of the previously mentioned models to predict PHRR, TTI, and Avg. HRR at 180 and 300 s. In addition, studies on generating synthetic data were performed by using generative adversarial networks (GANs) specialized for generating data to mimic the distribution of the training data to smooth out the distribution of the dataset.
For each polymer composition, the monomer was converted to a simplified molecular-input line-entry system (SMILES) string representation. This was chosen, as most cheminformatics methods for feature generation were based on this representation. The Mordred library was chosen for feature generation, allowing the generation of ~2000 features for each molecule as a unique fingerprint to link to its flammability characteristics [6]. Such fingerprints are common in developing models that predict molecular properties and behaviors, such as biological activities and physical-chemical properties, which are fundamental in drug design and other chemical informatics applications. Mordred generates features either based on two- or three-dimensional representations of the molecule.
By providing these extensive and efficiently calculated descriptors, Mordred provided a wide range of features for this application, particularly since these features proved to be effective in quantitative structure-activity relationship and quantitative structure-property relationship modeling. Its ability to generate a comprehensive set of molecular descriptors, coupled with its open-source accessibility and ease of use, made it a good fit for this work.
Model Training
Due to the limited amount of data available, a 95%–5% train-test split was chosen. Five-fold cross-validation was performed during training to mitigate overfitting. An ensemble of both classical and DL models was trained to compare their performance in predicting polymer flammability properties. These models were the Linear Regressor, Decision Tree Regressor, Deep Neural Network, Extreme Gradient Boosting (XGB) regressor (XGBoost), and Random Forest, as implemented in the Scikit Learn package. Specific implementation details for the algorithms are as follows:
- Two architectures for the deep neural network were explored—one with three hidden layers and one with six. For the network with three hidden layers, 256, 128, and 64 neurons were used for each layer. Rectified Linear Unit (ReLU) was chosen as the activation function for the neurons. The Adam optimizer was used for training the model with a learning rate of .001, and training was performed for 500 epochs.
- The DL network with six layers was tested with 512, 256, 128, 64, 32, and 5 neurons per layer. ReLU was chosen as the activation function for the neurons. The Adam optimizer was used for training the model with a learning rate of .001 and was trained for 50 epochs.
- The XGBoost algorithm was trained with the Squared Error objective function. All other parameters were left as defaults.
- The random forest model had 100 splits, with all other parameters left as defaults.
A simplified overview of the models used in this project is provided in the Discussion and Results section.
DFT Calculations
DFT calculations were performed using the CP2K simulation suite. Geometric optimization and electronic optimization calculations were performed for each of the unique polymer compositions in the FAA dataset. These simulations were performed using the Becke, three-parameter Lee-Yang-Parr (B3LYP) functional at the 6-31g** (split-valence double-zeta basis set, including polarization functions) level of theory. Performance was tested using central processing unit (CPU) and graphics processing unit (GPU) acceleration. Results showed that the boosts to performance on GPU were not relevant for the relatively small molecules studied. Therefore, these simulations were performed using an AMD EPYC 7413 CPU rather than an NVIDIA A100 GPU.
Discussion and Results
Model Selection on the FAA Cone Calorimetry Dataset
After implementing these models, regression evaluation metrics were chosen to downselect across the models. The regression metrics included mean squared error (MSE), square root of MSE (RMSE), mean absolute error (MAE), and coefficient of determination (R2). For MSE, RMSE, and MAE, lower values were desired. For an R2 score, higher was desirable. Metrics were averaged over several target variables, which were PHRR, average heat release rate (HRR) at 180 s, average HRR at 300 s, time to sustained ignition, and average specific extinction area.
Broadly, the limitations in the amount of data available significantly hindered the accuracy of the model across all metrics, despite the use of molecular fingerprints. Using MAE as a target metric, XGB and Random Forest performed best. Using R2 as a target metric, Random Forest and Linear Regression performed best. These results are shown in Figure 1, where comparing ML models with different metrics averaged over several target variables on the FAA data. R2 was 0.7 when averaging over several factors like polymer type; external heat flux and metrics such as peak heat release, time to ignition and char formation; and up to R2 of 0.93 for XGB on an average heat release at 300 s.
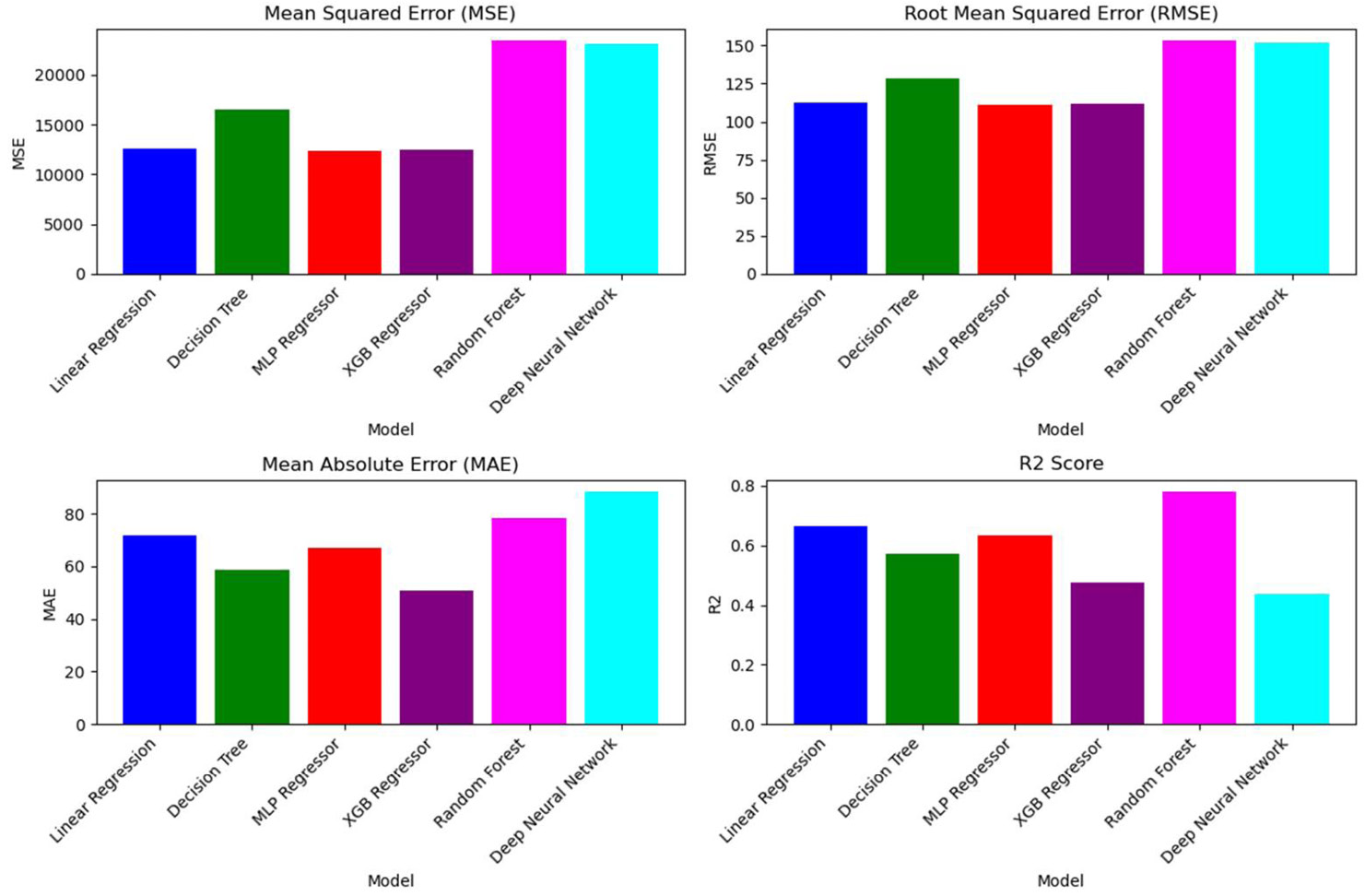
Figure 1. Predictions on the FAA Dataset (Source: G. M. Nishibuchi).
Decision trees, Random Forest, and XGB are similar algorithms, and XGB is often used in literature. For this reason, experiments with XGB continued in this analysis.
Feature Selection: Training With and Without DFT Features
Limitations were necessary on the amount of data that could be obtained from the DFT calculations regarding whether the highest energy occupied molecular orbital (HOMO)-lowest energy unoccupied molecular orbital (LUMO) gap and free energies from the DFT calculations made a meaningful impact on model performance. Thus, model training was performed with and without DFT features. With the DFT features included, MSE, RMSE, and MAE all rose and R2 scores fell (Figure 2).
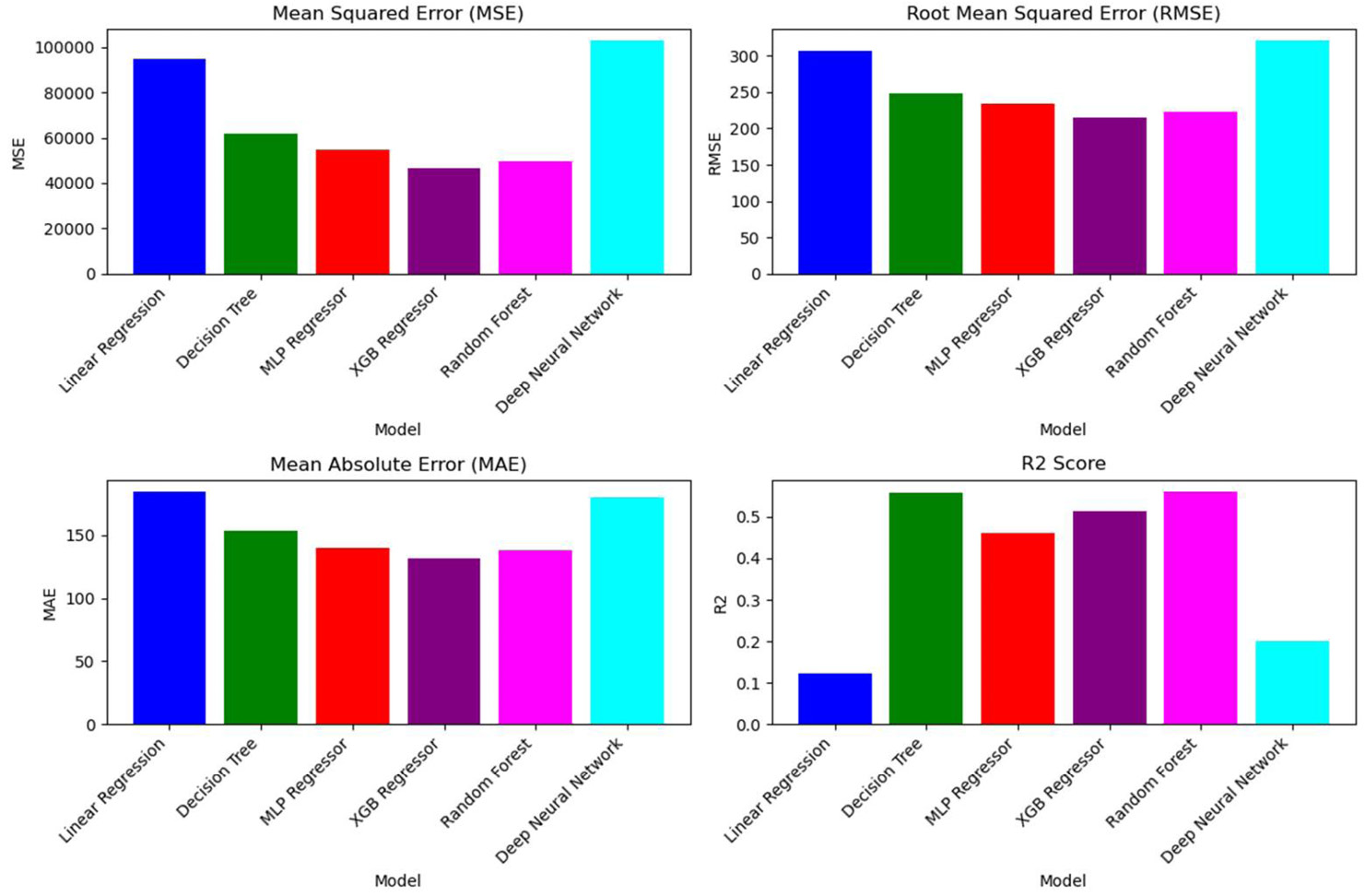
Figure 2. Comparison of Models Averaged Over Several Target Variables on the FAA Data (Source: G. M. Nishibuchi).
Tree-based models like XGBoost can generate feature importance values, which track how many times a feature is used to split a node in the decision tree. Each split reduces the Gini impurity, thus reducing the likelihood of the model selecting a random point in the dataset. The features with the highest amount of attributed splits can be considered the most important toward making a correct prediction.
Figure 3 shows the 10 highest importance Mordred features for PHRR (left) and TTI (right). Mordred features can be difficult to describe succinctly (e.g., GATS3are is the Geary coefficient of lag 3 weighted by Allred-Rochow electronegativity) but are understood by computational chemists and repeatable.
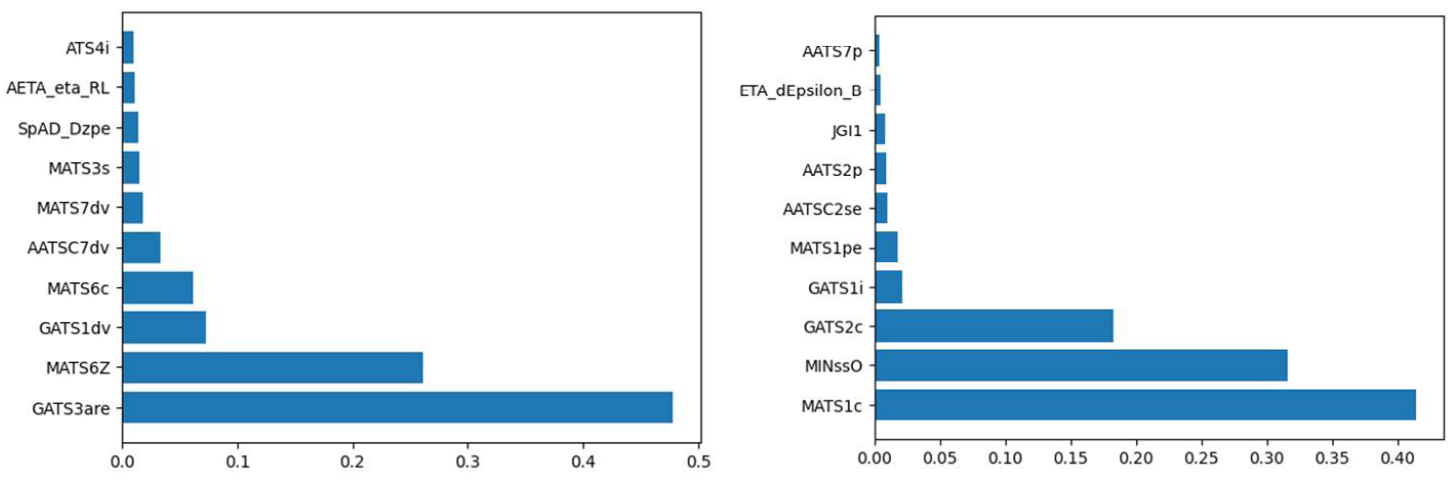
Figure 3. Feature Importance Across a Subset of Mordred Features for PHRR (Left) and TTI (Right) (Source: G. M. Nishibuchi).
Synthetic Data Generation Effects on Prediction Metrics
GANs are ML algorithms that generate synthetic data mimicking real data. A GAN consists of two neural networks—the generator and the discriminator. The generator creates fake data from random noise, aiming to produce data indistinguishable from real data. The discriminator evaluates both real and fake data, attempting to distinguish between them. The generator and discriminator are trained simultaneously in an adversarial process. The generator improves by creating more realistic data to fool the discriminator, while the discriminator enhances its ability to detect fake data. GANs have been applied successfully in various fields, including image and video generation, text creation, and data augmentation, due to their ability to generate high-quality synthetic data. While stable diffusion has generally taken over the image generation space (e.g., the DALL-E series of models), GANs have proven effective in the domain of generating tabular data.
A variety of synthetic tabular data generation models was tested, including variational autoencoders, diffusion models, CTGANs, triplet-based VAE, bootstrapping, and a Gaussian copula synthesizer. A dataset containing ~36,000 samples was created based off the data contained in the FAA database and significantly improved the performance across multiple ML and DL models, with metrics shown in Figure 4.
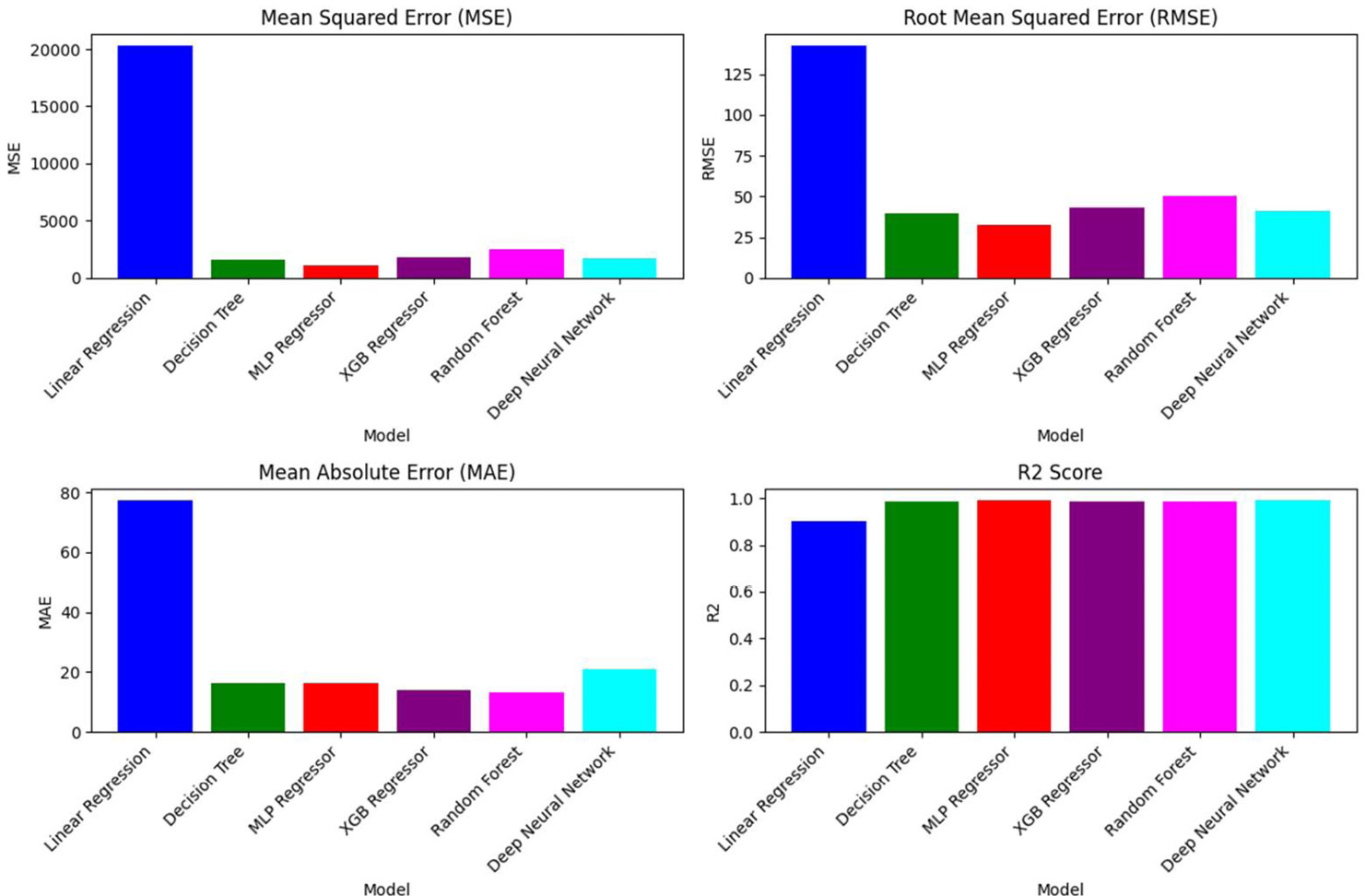
Figure 4. Comparison of Model Metrics for Predicting PHRR With (Top) and Without (Bottom) Synthetic Data (Source: G. M. Nishibuchi).
Composite Prediction
Composites of multiple polymers are a particularly difficult problem for predicting polymer flammability due to the limited amount of data existing for the neat resins alone. However, composites often provide favorable material properties compared to the properties of the individual neat resins; thus, it is necessary to predict the flammability characteristics of polymer composite systems. A methodology for predicting the properties of polymers was formulated as a weighted sum of the properties of the components of a composite or a polymer with additives. The calculation is formalized as follows:
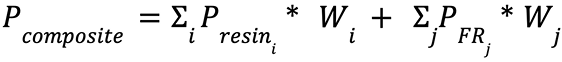 , (1)
, (1)
where Pcomposite is the composite property of interest (PHRR, TTI, etc.), Presin,i is the predicted property of the individual polymer component, Wi is the mass percentage of the polymer component, PFR,j is the predicted property for a flame retardant/additive, and Wj is the mass percentage of the flame retardant/additive. This allows the user to get a sense of the range of potential predictions and decide which values are best to use/not use (e.g., in the case of an obvious outlier). This also helps in identifying which models struggle with predicting certain parameters so the user can choose to retrain the models on different/altered data to improve performance or choose a different model for predictions.
Study on Polymers With Flame Retardants (FRs) and Fillers
TAMU’s Prof. Wang developed a dataset of polymer flammability before and after the addition of FRs. The TAMU dataset was used to predict the flame retardancy index (FRI), TTI, total heat release (THR), and PHRR given several input features. Raw features and custom features were combined as input variables to improve model performance. The features in the dataset are explained as follows:
- Flammability: Baseline flammability of the pure polymer.
- TGAP: Thermal stability of the pure polymer.
- Nanofiller loading (wt): Amount of nanofiller added.
- dTGA: Change in thermal stability due to nanofiller.
- Dimension: Shape and form factor of the nanofiller.
- Type: Material composition of the nanofiller.
- IFR: Presence of intumescent flame retardant.
The custom features are given as follows:
- Average TGA: Average of the TGA values before and after flame-retardant treatment.
- Polymer and Type: Combines the polymer type and another categorical feature and type into a single feature, creating a combined categorical feature that uniquely identifies the combination of polymer type and another characteristic.
- IFR Flammability Ratio: Ratio of flammability to the presence of an intumescent flame retardant. The ratio aims to quantify the flammability relative to the presence of an intumescent flame retardant. Adding 1 to the IFR value ensures the denominator is never zero, preventing division errors. This feature can highlight how flammability changes with and without the flame retardant.
- Flammability: Represents the flammability measurement of the sample.
- IFR: A binary feature indicating the presence (1) or absence (0) of an intumescent flame retardant.
- Polymer and Incorporated Nanoparticles: Combines the polymer type and the type of incorporated nanoparticles into a single feature, creating a combined categorical feature that uniquely identifies the combination of polymer type and incorporated nanoparticles. This can capture the specific interactions between the polymer and the type of nanoparticles used, which could be relevant for the model.
Using these input variables, models were trained to predict the following target variables: After FR TTI, PHRR, THR, and FRI. Regression metrics across the trained models and averaged over several target variables on the TAMU dataset are shown in Figure 5. Performance was acceptable, with up to a 0.8 R2.
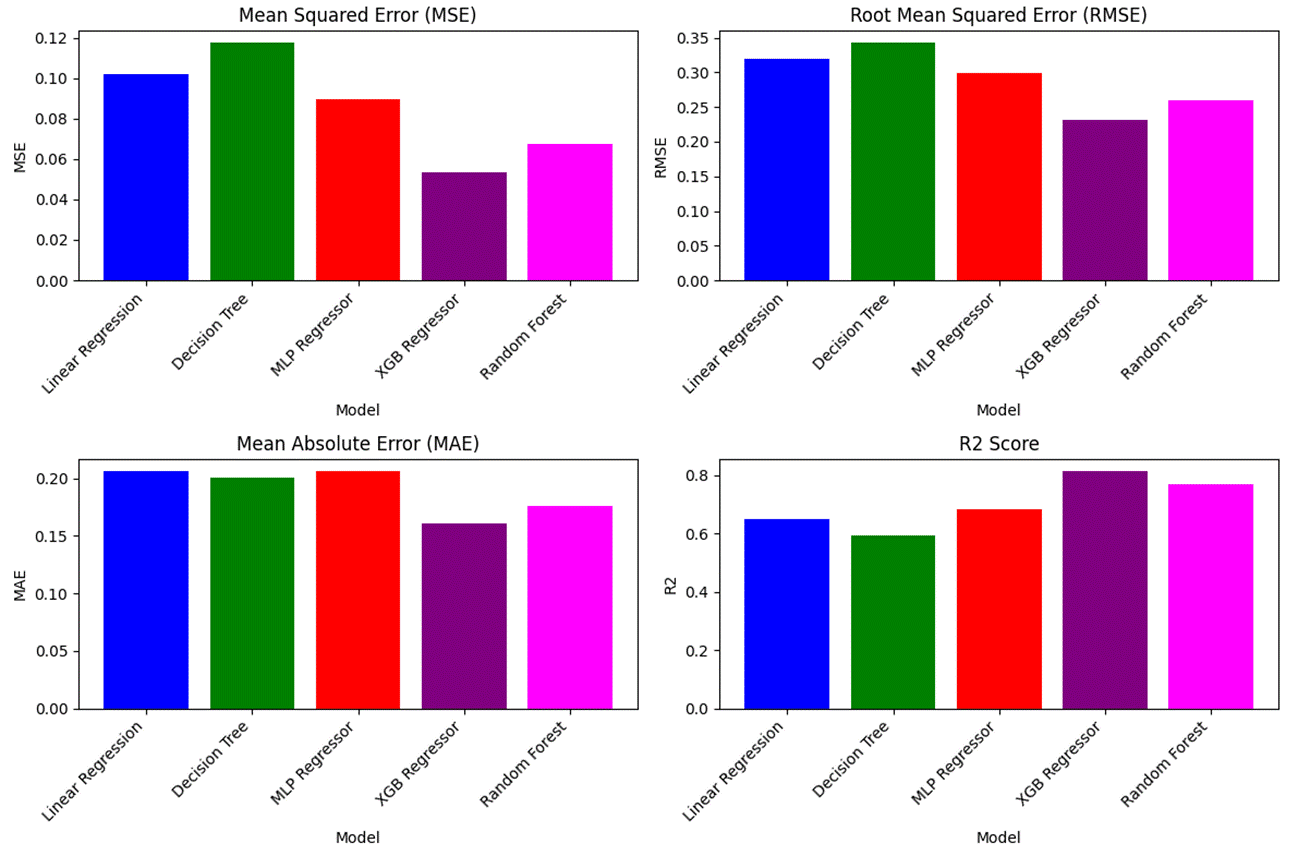
Figure 5. Comparison of ML Models With Different Metrics (Source: G. M. Nishibuchi).
XGB outperformed all other models in terms of MSE, RMSE, MAE, and R2. As with the FAA dataset, feature importance was also examined. Using a Random Forest classifier, which is similar to XGB, the feature importance for each target variable was shown. Before FR TTI, PHRR and THR were important. In incorporated nanoparticles, percent weight was also important. Feature importance values from the XGBoost model are shown in Figure 6 for the four target variables.
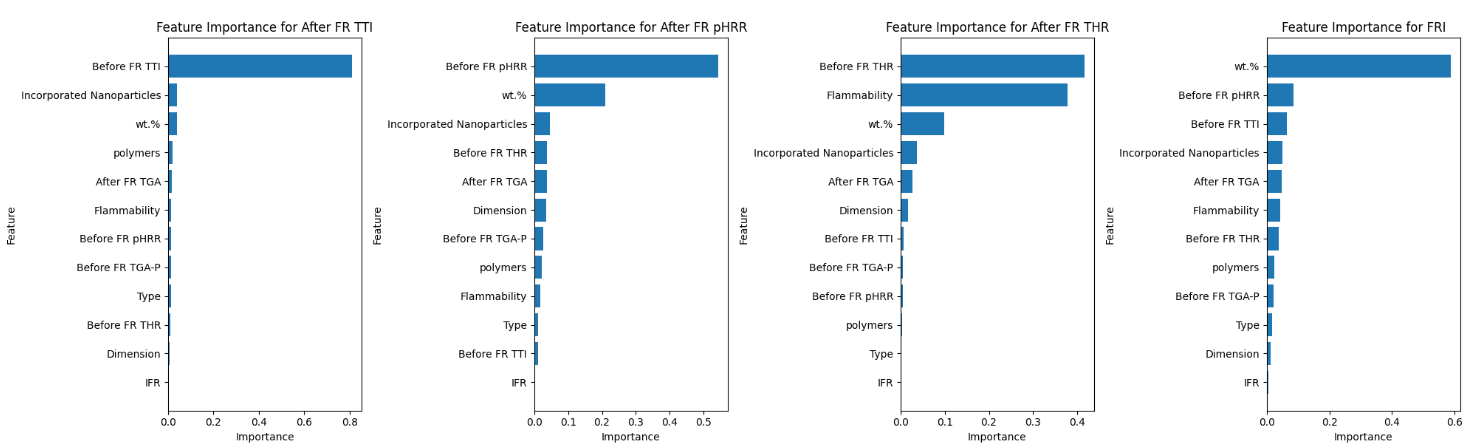
Figure 6. Top Feature Importance Values for Different Target Variables From the XGBoost Model (Source: G. M. Nishibuchi).
DFT Simulations
It was found that the CP2K software suite was better optimized for the CPU than the GPU, with optimization iteration times being an order of magnitude lower than on the GPU. DFT software applications are generally written using Fortran due to its high efficiency and extremely well-established set of linear optimization and matrix multiplication libraries that are core parts of any DFT software. Because of the high complexity of these software applications, they have also been slow to uptake modern GPUs designed for the matrix operations used in linear optimization and matrix multiplication. The poor GPU performance relative to CPU observed in CP2K is a possible result of years of CPU optimization being compared to a relatively new and unoptimized GPU implementation. Another key contributor to this issue is the fact that the monomer system sizes are likely not large enough to benefit from the use of massively parallelized GPUs.
A study from Los Alamos National Laboratory that involved performance benchmarking comparisons between CPU- and GPU-based CP2K implementations showed up to a 3.7× boost in performance on a GPU system compared to an identical simulation on a CPU [7]. Their system size was on the order of 900 atoms, and they did observe a significant boost in performance at the much larger system size. It is highly likely that small system sizes (<50 atoms) under study did not necessitate the high-throughput advantages of the GPU, and the increased amount of overhead from GPU-CPU memory transfers led to longer runtimes compared to the CPU-only implementation.
In Figure 7, one incorrect calculation was observed for the free energy of polyvinyl fluoride due to an issue with the geometric optimization’s convergence. While polyethylene’s HOMO-LUMO gap appears to be an outlier, it was evaluated against literature values and found to be consistent. In a larger system, this gap would decrease because of conjugated bonds in the larger polymer chain.
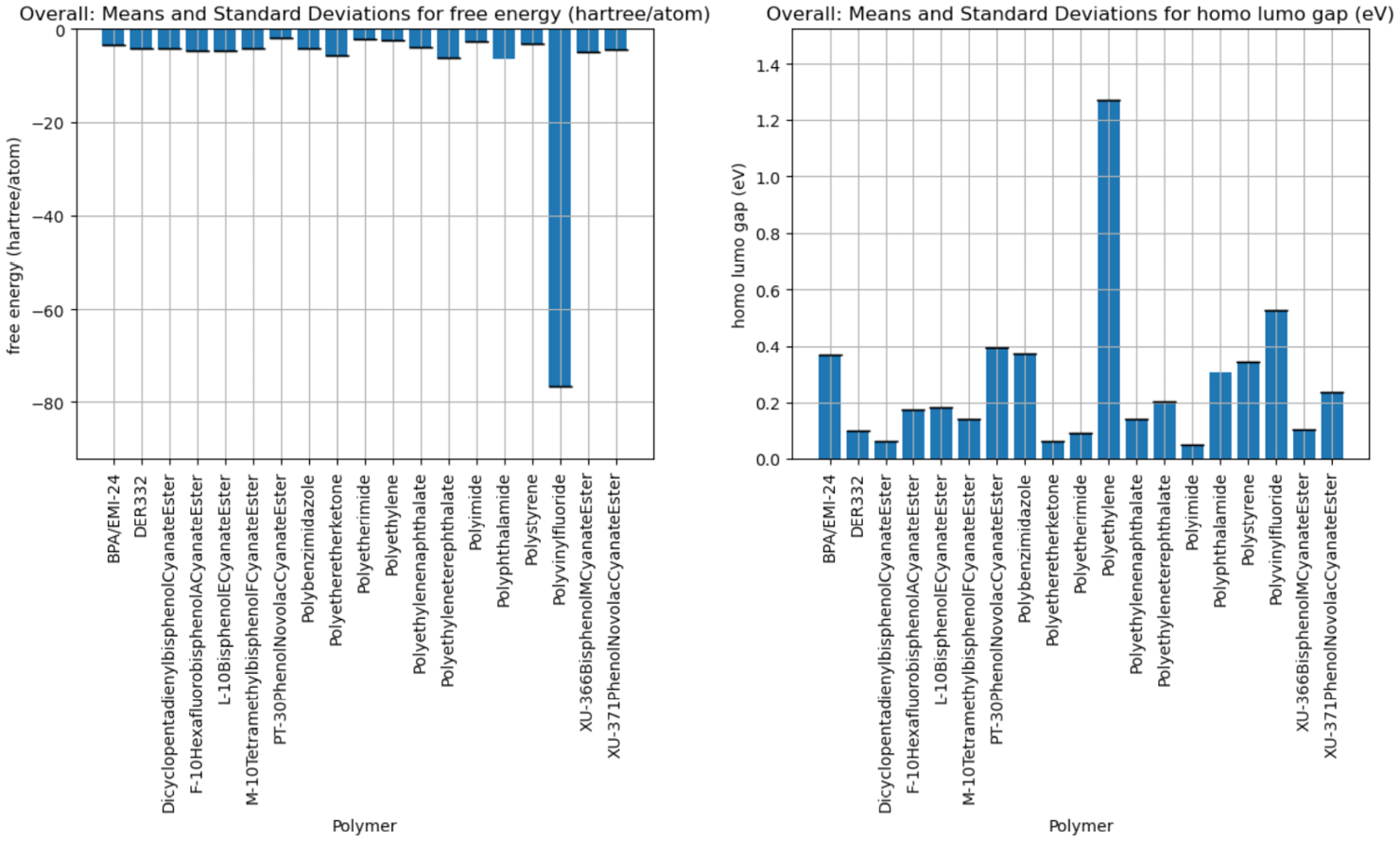
Figure 7. Free Energy (Left) and HOMO-LUMO Gap (Right) for the Unique Polymer Compositions in the FAA Database, Obtained via DFT Simulations (Source: G. M. Nishibuchi).
Conclusions
Predicting macroscale cone calorimeter measurements from atomistic features comes with a wide variety of challenges, both theoretical and practical. This work demonstrated the development of molecular fingerprints for predicting polymer flammability, first principles simulations of neat resins, and the development of ML and DL molecules for predicting ASTM E1354 experimental measurements from DFT, experimental, and molecular properties. The use of ensemble prediction was found to be effective in the low data domain of ASTM E1354 experimentation. Continued work in developing standardized databases for storing cone calorimetry data is imperative for further development of ML methods to predict polymer flammability.
Acknowledgments
This material was based upon work supported by the U.S. Office of Naval Research under award number N6833524C0125.
References
- Lyon, R. E., et al. “A Statistical Model for the Results of Flammability Tests.” Conference Proceedings – Fire and Materials, The 11th International Conference and Exhibition, 2009.
- Hergenrother, P., et al. “Flame Retardant Aircraft Epoxy Resins Containing Phosphorus.” Polymer, vol. 46, no. 14, pp. 5012–5024, https://doi.org/10.1016/j.polymer.2005.04.025, 2005.
- Ma, T., et al. “Thermal Degradation and Flame Retardancy Prediction of Fe, Al, and Cu-Based Metal-Organic Framework and Polyethylene Terephthalate Nanocomposites Using DFT Calculation.” Polymer, vol. 263, p. 125496, https://doi.org/10.1016/j.polymer.2022.125496, 2022.
- Nguyen, H. T., et al. “Predicting Heat Release Properties of Flammable Fiber-Polymer Laminates Using Artificial Neural Networks.” Composites Science and Technology, vol. 215, p. 109007, https://doi.org/10.1016/j.compscitech.2021.109007, 2021.
- U.S. DoD. Fire and Toxicity Test Methods and Qualification Procedure for Composite Material Systems Used in Hull, Machinery, and Structural Applications Inside Naval Submarines. MIL-STD-2031, 26 February 1991.
- Moriwaki, H., Y.-S. Tian, N. Kawashita, and T. Takagi. “Mordred: A Molecular Descriptor Calculator.” Journal of Cheminformatics, vol. 10, no. 4, doi: 10.1186/s13321-018-0258-y, 2018.
- Yokelson, D., N. V. Tkachenko, R. Robey, Y. W. Li, and P. A. Dub. “Performance Analysis of CP2K Code for Ab Initio Molecular Dynamics on CPUs and GPUs.” Journal of Chemical Information and Modeling, vol. 62, no. 10, pp. 2378–2386, https://doi.org/10.1021/acs.jcim.1c01538, 2022.
Bibliography
Glassman, I., and R. A. Yetter. Combustion. Academic Press, 2008.
Goodstein, D. L. States of Matter. Dover Publications, Inc., 2017.
Lyon, R. E., et al. “A Molecular Basis for Polymer Flammability.” Polymer, vol. 50, no. 12, pp. 2608–2617, https://doi.org/10.1016/j.polymer.2009.03.047, 2009.
Lyon, R. E., et al. “Fire-Resistant Aluminosilicate Composites.” Fire Mater., vol. 21, pp. 67–73, https://doi.org/10.1002/(SICI)1099-1018(199703)21:2<67::AID-FAM596>3.0.CO;2-N, 1997.
Pomázi, A., et al. “Predicting the Flammability of Epoxy Resins From Their Structure and Small-Scale Test Results Using an Artificial Neural Network Model.” Journal of Thermal Analysis and Calorimetry, vol. 148, no. 2, pp. 243–256, https://doi.org/10.1007/s10973-022-11638-4, 2022.
Quan, Y., Z. Zhang, R. N. Tanchak, et al. “A Review on Cone Calorimeter for Assessment of Flame-Retarded Polymer Composites.” Journal of Thermal Analysis and Calorimetry, vol. 147, pp. 10209–10234, https://doi.org/10.1007/s10973-022-11279-7, 2022.
Stoliarov, S. I., et al. “Prediction of the Burning Rates of Non-Charring Polymers.” Combustion and Flame, vol. 156, no. 5, pp. 1068–1083, https://doi.org/10.1016/j.combustflame.2008.11.010, 2009.
Tao, Q., et al. “Machine Learning for Perovskite Materials Design and Discovery.” Computational Materials, vol. 7, no. 1, npj, https://doi.org/10.1038/s41524-021-00495-8, 2021.
Biographies
George M. Nishibuchi is a senior ML engineer and computational materials scientist at Quantum Ventura Inc. He has run over 50,000 DFT simulations as a researcher at Purdue University’s Network for Computational Nanotechnology, from high-throughput studies of semiconductors to mechanistic studies in solid-state electrolytes. Mr. Nishibuchi holds a B.S. and M.S. in materials engineering from Purdue University.
Suhas Chelian is a researcher and ML engineer at Quantum Ventura Inc. He has captured and executed more than $12 million worth of projects with several organizations like Fujitsu Labs of America, Toyota (Partner Robotics Group), Hughes Research Lab, the Defense Advanced Research Projects Agency, the Intelligence Advanced Research Projects Agency, and the National Aeronautics and Space Administration. He has 31 publications and 32 patents demonstrating his expertise in ML, computer vision, and neuroscience. Dr. Chelian holds dual bachelor’s degrees in computer science and cognitive science from the University of California San Diego and a Ph.D. in computational neuroscience from Boston University.
Wyler Zahm is a senior ML engineer at Quantum Ventura Inc. He has worked with advanced algorithms, front- and back-end development, a variety of artificial intelligence (AI)/ML architectures and frameworks like full precision/GPU and reduced precision/neuromorphic technologies, and applications like automated vulnerability detection and repair for computer source code and cybersecurity. Mr. Zahm has dual bachelor’s degrees in computer engineering and data science from the University of Michigan.
Srini Vasan is the president and chief executive officer at Quantum Ventura Inc. and chief technology officer at QuantumX, the research and development arm of Quantum Ventura Inc. He specializes in AI/ML, AI verification and validation, ML quality assurance and rigorous testing, ML performance measurement, and system software engineering and system internals. Mr. Vasan studied management at the MIT Sloan School of Management.
Richard E. Lyon is program director at the FAA. He has invented many of the techniques used for polymer and composite materials analysis regarding flammability and polymer composites by hand for the Navy. He has written landmark papers on the study of polymers, composites, and their properties, including relevant experiments at the Lawrence Livermore National Laboratory and the FAA. Dr. Lyon holds a Ph.D. in polymer science and engineering from the University of Massachusetts Amherst.